Strongly-Typed Data Model Validation using Fluent Validation - C# .Net Core
Missing Data Required
Data model validation is critical when concerning data integrity in your software implementation. For quite some time we’ve had access to the DataAnnotations namespace and the [Required] attribute, however this isn’t always the most flexible solution to the problem…
The Downside of DataAnnotations
So you’re looking to validate that data model you’ve developed in C#. The minute you use DataAnnotations you are binding your validation rules to your underlying data model…not exactly “separation of concerns” is it?
The [Required] attribute doesn’t provide the most amount of control over your validation rules out of the box either, and finally, unit testing becomes far more complicated if you choose to use DataAnnotations.
Introducing “Fluent Validation”
You’ll remember in my previous blog post about building a cross-platform RESTful SMS API using Twilio, that I implemented some basic model validation using the FluentValidation package. Numerous people were keen to know more, so let’s dig a little deeper with fluent validation in today’s blog…
Code Time…
The first thing to establish is a simple data model. In this case we’re going to base it on some common “user account” fields, with a few extras specifically to show how FluentValidation works with different data types.
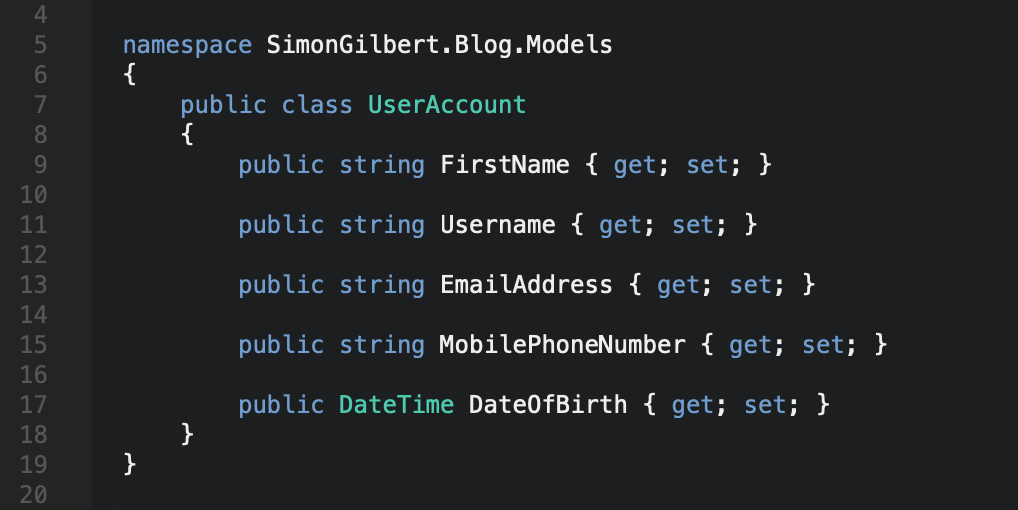
C# .Net Core FluentValidation - Data Model
The next thing to do is pull in a copy of the FluentValidation package from Nuget…
Now that’s done, we can begin to write our validation code. Your validator class will need to inherit from FluentValidation’s AbstractValidator class, with the type being that of the data model we have just created. We can then start to make use of the RuleFor functionality, to establish validation rules for each model property.
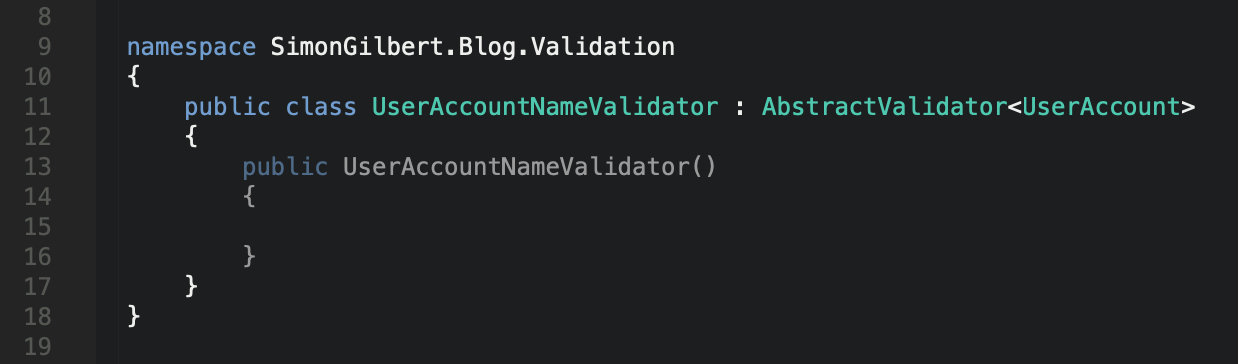
C# .Net Core FluentValidation - Abstract Validator
Basic Validation
Now let’s add some basic validation for our FirstName property, to ensure that it isn’t null and that it has a length of 2 - 50 characters. You’ll note that the syntax is similar to LINQ, and that we’re adding multiple checks together - known as “validator chaining”.
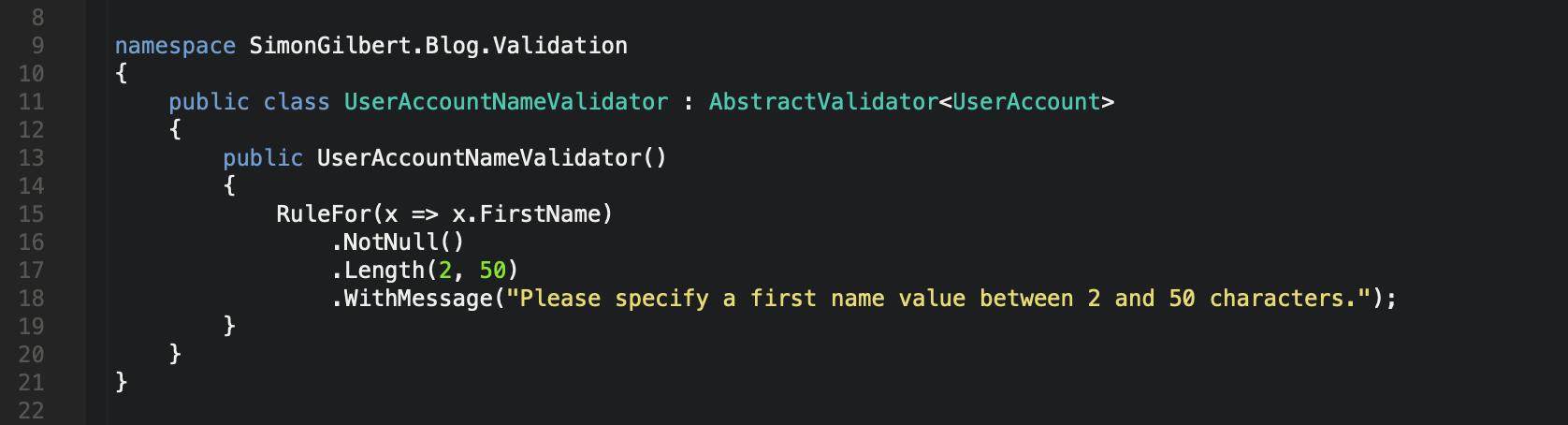
C# .Net Core FluentValidation - Basic Validation
Validator Chaining
Let’s extend on this chaining concept next by chaining a validation method to our username property, followed by chaining a message which we return to the user if the validation for this property fails.
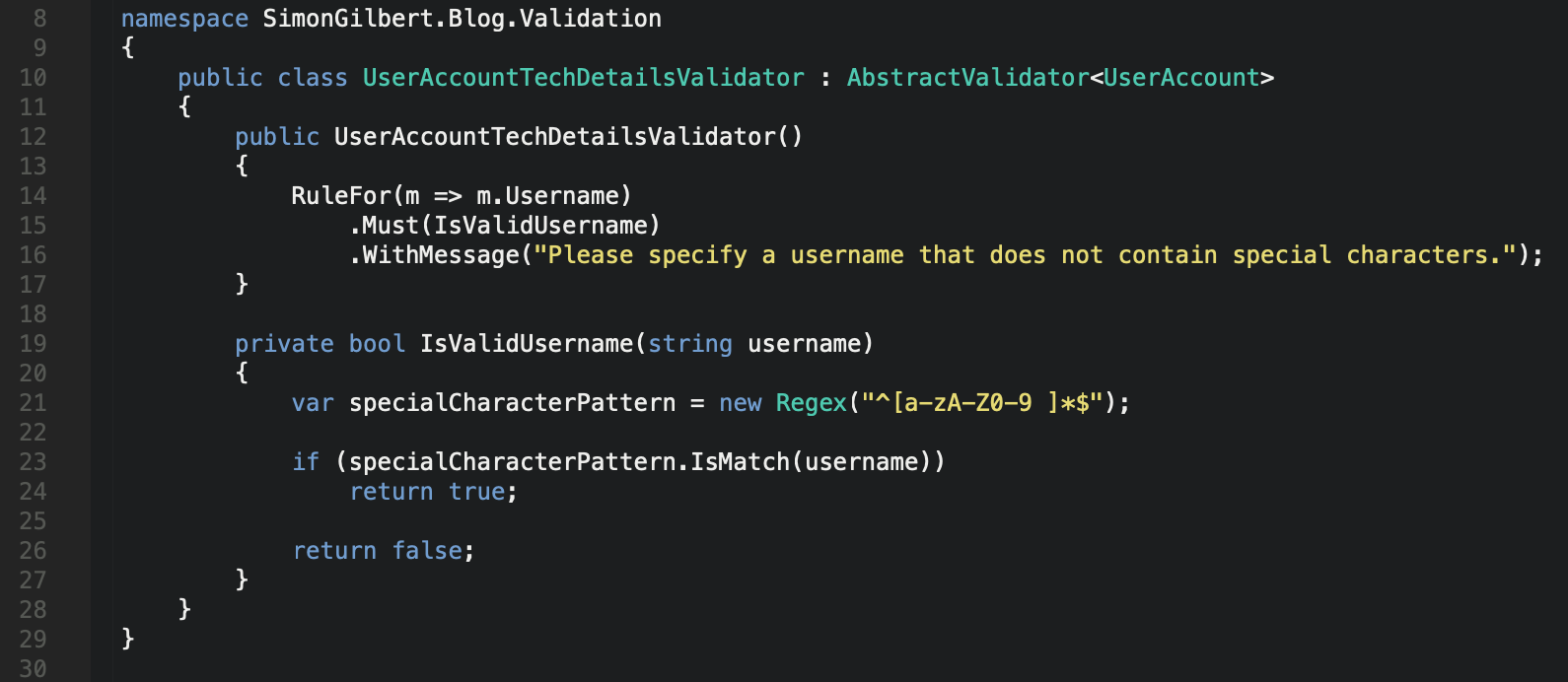
C# .Net Core FluentValidation - Validator Chaining
As you can see, we’re using a regex within a separate method to check that the username does not contain special characters. We’ve chained the regex method to the relevant property using the Must() method, and in the event that validation fails, we return an error message which we’ve chained to the properties overall validation using the WithMessage() method.
Extending Our Validation & Regex Usage
Our data model accepts an email address and a UK mobile phone number too, so let’s build out some more validation for these methods using Regex and the same validation chaining concepts.
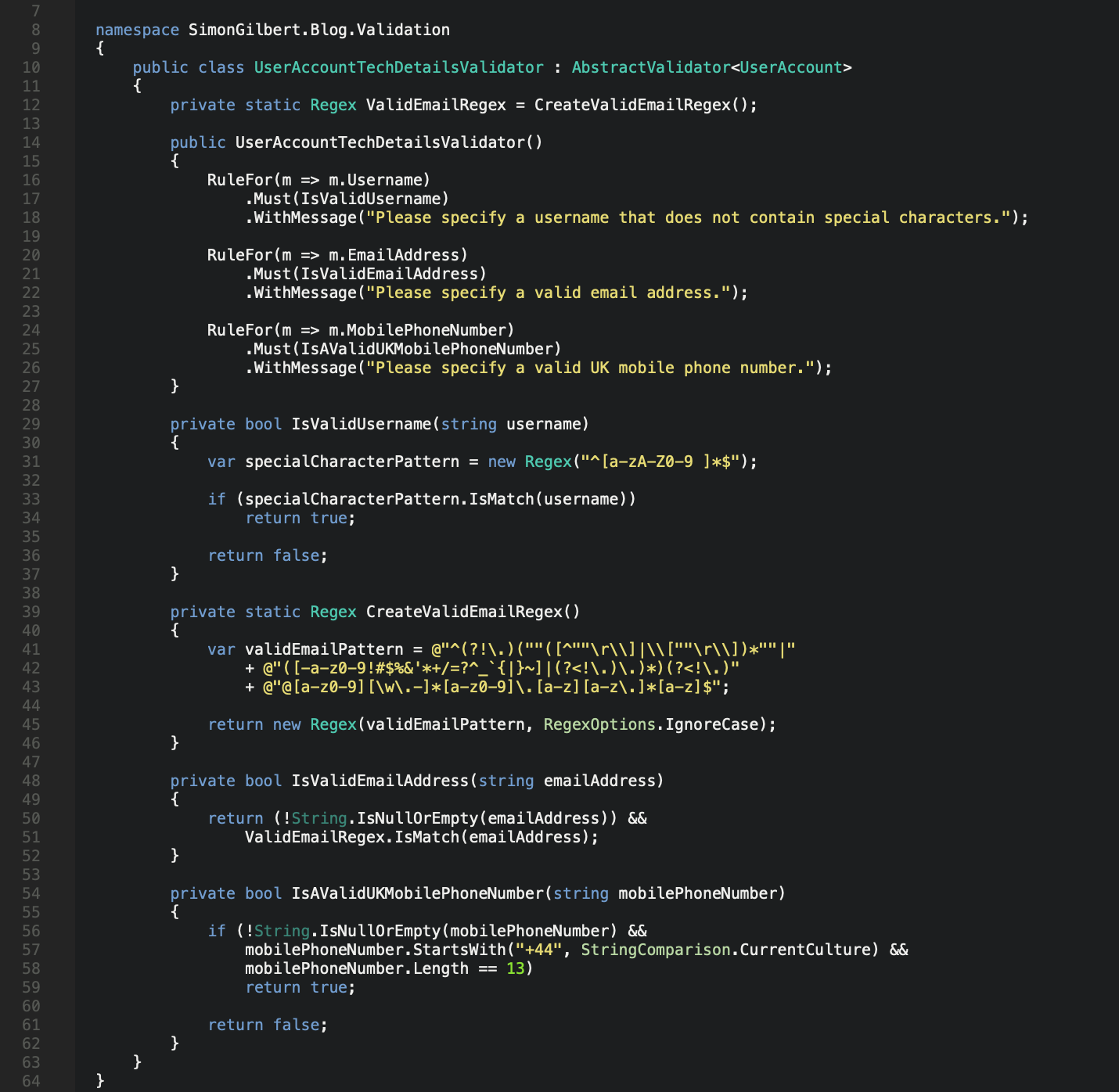
C# .Net Core FluentValidation - Extended Validation
Another Separate Validator
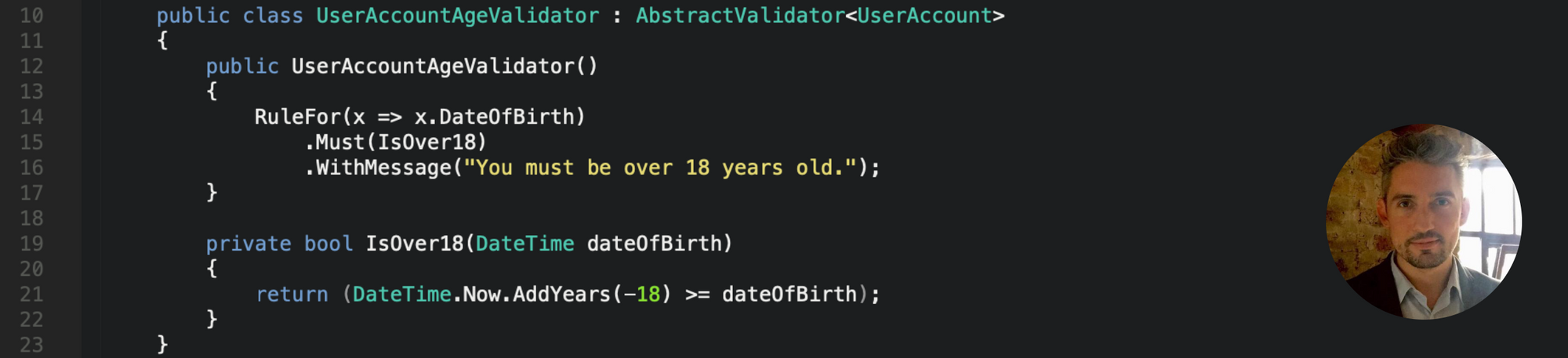
Continuing to adhere to separation of concerns, let’s create another separate validator which is specifically designed to validate that the date of birth property on our user account data model is a date which indicates that the user is at least 18 years old.
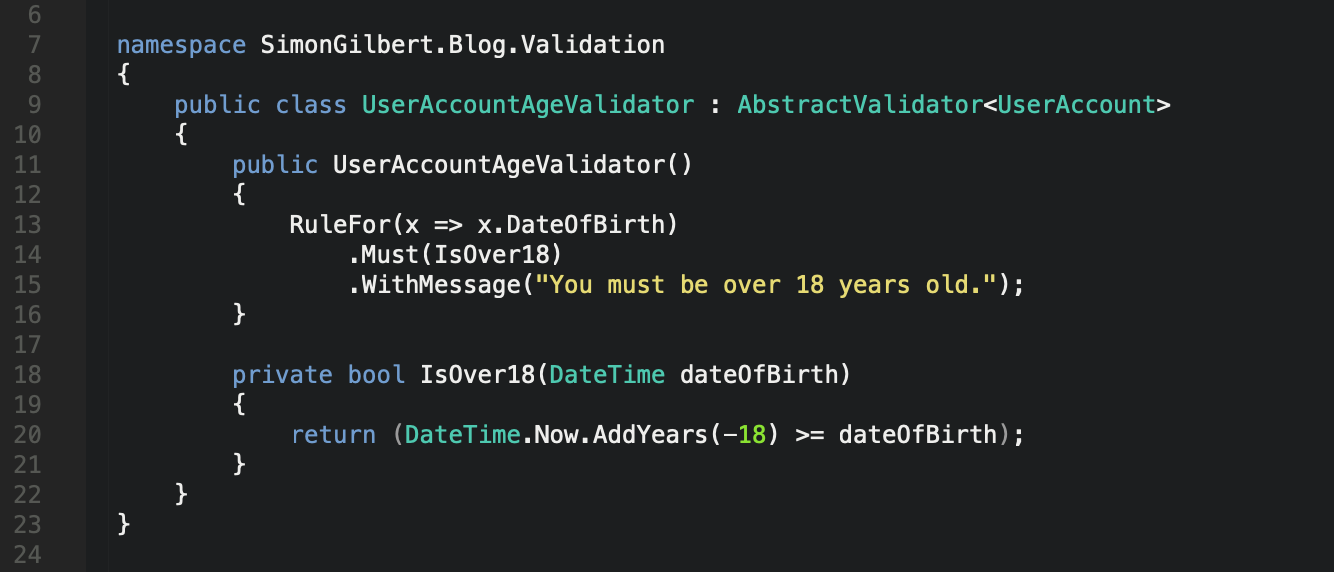
C# .Net Core FluentValidation - Separate Validator
Including & Grouping Our Separated Validators
At this point we have three validators, one which allows us to validate the user account data models first name property, another which validates the username, email address and mobile phone number properties are inline with our required rules, and finally a third validator which checks the date of birth (age) property.
Now let’s group them and include them into a single validator class.
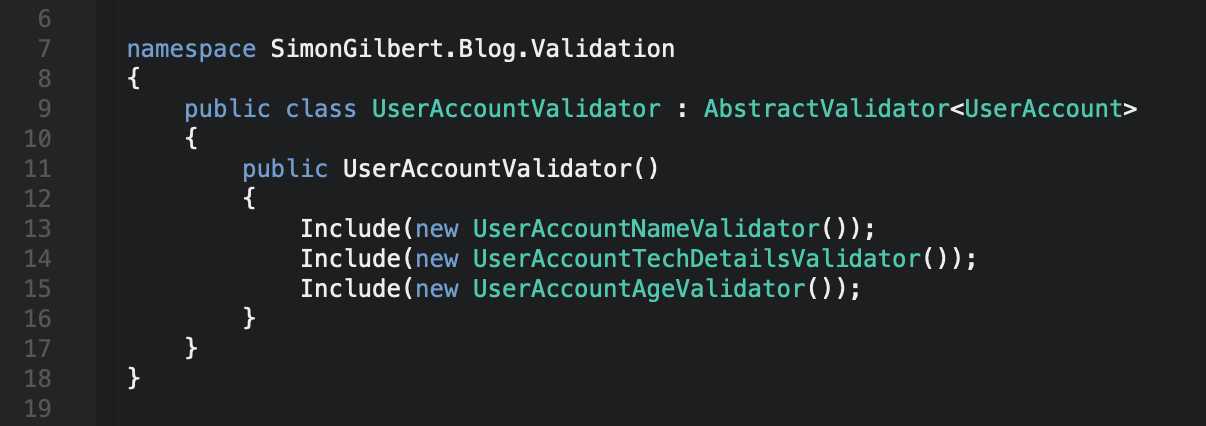
C# .Net Core FluentValidation - Including & Grouping
This allows us to fully separate out our validation code whilst still grouping the related rules together - Thus, nice, clean, code!
Testing Our Validation Using xUnit
Now it’s time to unit test our validation rules using the glorious xUnit Framework and two very basic unit tests.
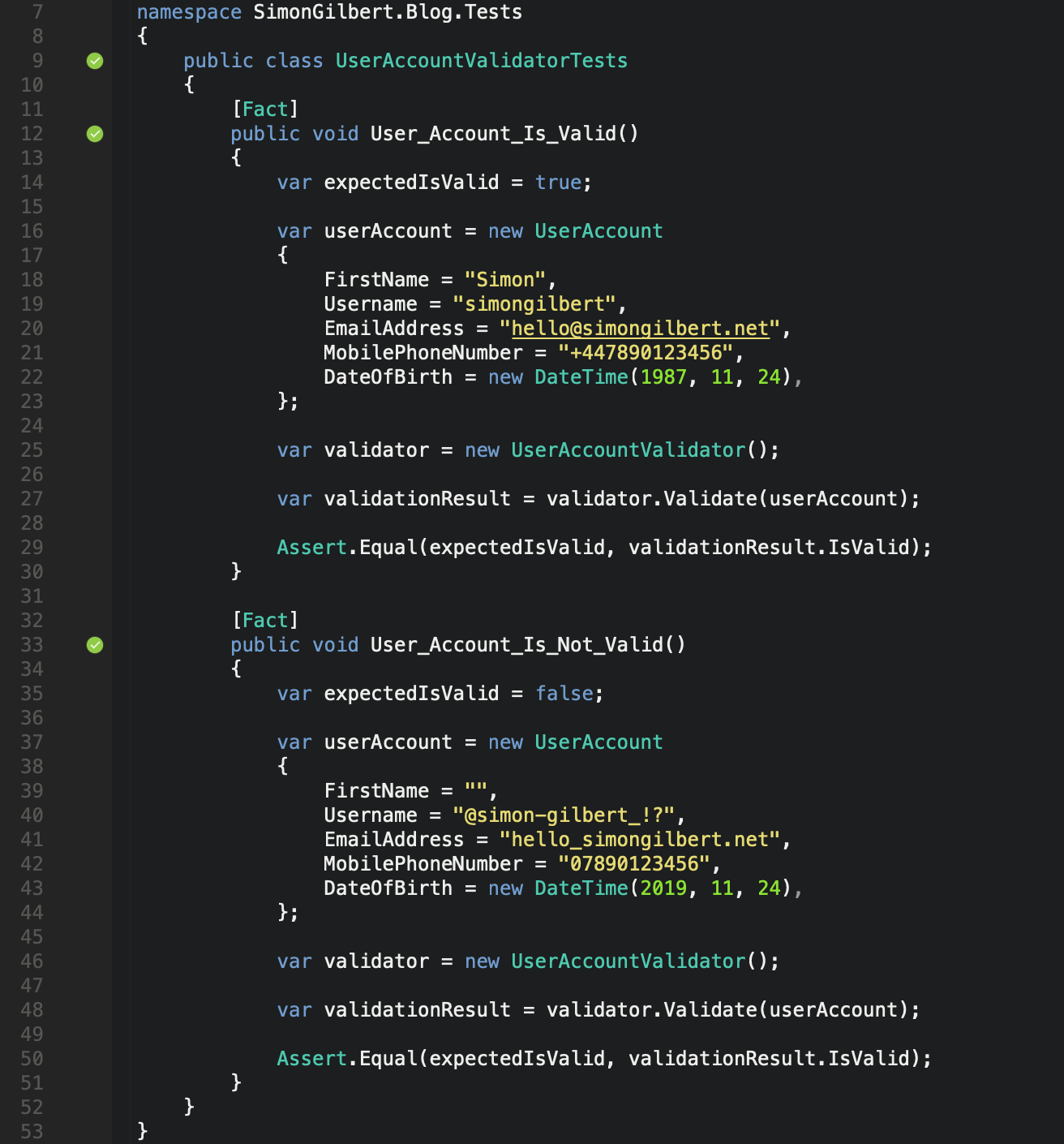
C# .Net Core FluentValidation - xUnit Tests
Here are the results of our unit tests, as expected…
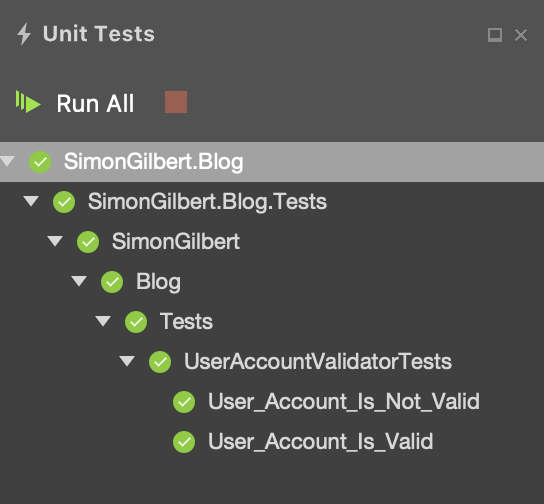
C# .Net Core FluentValidation - xUnit Test Results
Validation Error Messages On Exception
Let’s try running a completely invalid data model submission, using the FluentValidation ValidateAndThrow method -
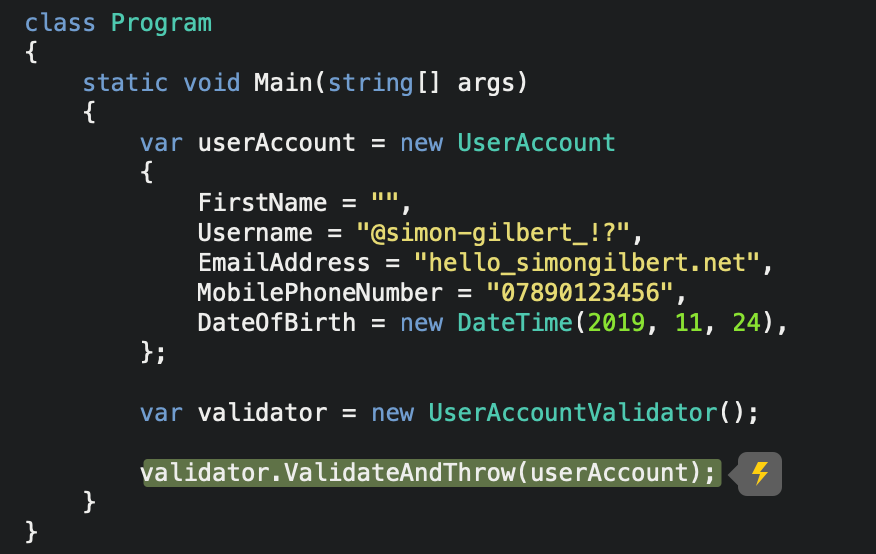
C# .Net Core FluentValidation - ValidateAndThrow
…and now to view the validation exception in all it’s glory, with our error messages as expected.
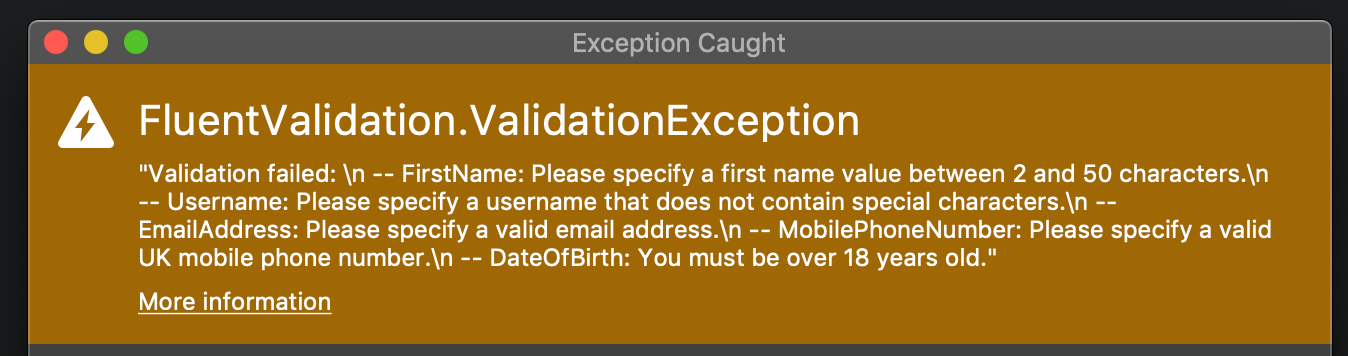
C# .Net Core FluentValidation - ValidateAndThrow Exception
…like I mentioned, your validation rules are much cleaner and data integrity is no longer a painful process.
Enjoy!