Using Serverless Azure Functions (FaaS) to write Service Bus Topic messages to NoSQL Azure Table Storage
Remember The Publish-Subscribe Pattern?
You’ll remember previously I discussed implementing the publish-subscribe pattern using Microsoft Azure’s Service Bus - specifically through making use of topics and subscriptions.
Thinking back to that scenario, the purpose of the design is to allow you to spin up as many subscribers as necessary to handle the throughput from the message queue. There may even be scenarios where you want to process that data, or simply write it to a database for another service to analyse later on. In order to do that efficiently, you could make use of event-driven architecture that can act when triggered by receipt of the queues messages…
Serverless Architecture FTW?
“Serverless architectures are application designs that incorporate third-party “Backend as a Service” (BaaS) services, and/or that include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform.”

Serverless Microsoft Azure Functions (FaaS)
In recent years serverless architecture has become all the rage and there are many reasons for this. In some cases “serverless” is referred to as “Backend as a Service” (BaaS), and in others it’s “Functions as a Service” (FaaS). Ultimately it depends on what you’re leveraging in your implementation, but first let’s define some key characteristics of serverless.
Serverless Characteristics
- Business Logic Focused - The developers only need to focus on writing the code, not on the infrastructure to run it on.
- 3rd Party Reliant - Significantly Incorporate cloud-hosted services to manage the system.
- Event-Driven Architecture - Your source code will only run when an event fires (which is often referred to as a “trigger”).
- Managed Infrastructure - Your server and operating system are fully managed, maintained and upgraded as and when necessary, by your provider.
- Ephemeral Process (FaaS) - Short task execution, may only last for one invocation - The exact opposite of long running server processes.
- Auto-Scaling - Your service will scale in parallel with the throughput. There’s no need to buy an octa-core processor for day 1 before your user base picks up…
- Reduced Operational Cost - As a by-product of not needing to run as an “always on” component, this can lead to a significantly reduced operational cost.
…"serverless" doesn’t actually mean there isn’t a server…it simply means that you don’t have to look after the hardware or processes when running your code, as it’s fully outsourced to a provider…
Enter “Azure Functions”…
Azure Functions allow you to run small pieces of code in the cloud, without having to worry about the underlying architecture that the codebase is running on. The beauty of this is that it means we only have to worry about the logic we’re writing, and nothing else…Microsoft Azure will determine the necessary infrastructure required to run your Azure Function on demand…all, by, itself.

Serverless Microsoft Azure Functions (FaaS)
Another thing to note is that Azure Function’s don’t only support C#, they also support Python, JavaScript and Java too!
Azure Function Execution - “Triggers”
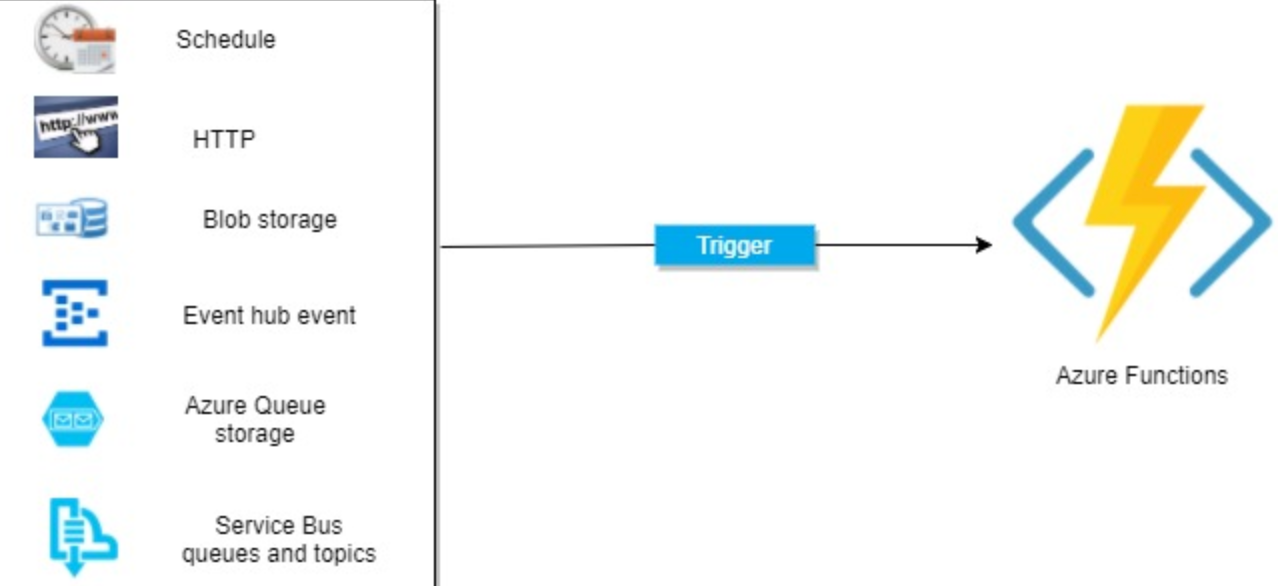
Your Azure Function is a self-contained codebase. The Function waits to be executed by a Trigger - something that listens to external services, waiting for specific events to occur. Upon the event occurring, the Function fires up in response. There are numerous types of Triggers that can be used to start the Function, including elapsed timers, container BLOB insertion and message queues.
A Function can only have one Trigger, and a Trigger has data associated with it which is often the payload of the Function.
Different Types of Triggers
Your Azure Function can utilise different types of Triggers, so let’s briefly cover some of the main Triggers -
- HTTPTrigger: Triggered when an HTTP request is received.
- TimerTrigger: This trigger executes on a pre-determined schedule that you define.
- BlobTrigger: Triggered when a new or updated BLOB is detected.
- ServiceBusTrigger: Triggers when any new messages are received from an Azure Service Bus first-in-first-out queue.
Serverless Microsoft Azure Functions (FaaS)
External Service “Bindings”
Azure Functions come with “Bindings” too, which affectively act as a way of declaratively connecting another resource to your Function, either as input/output/both. Bindings are optional, and you can mix and match them with Triggers.
Azure Function Flow
Your Azure Function receives data (e.g. Azure Service Bus Queue messages through a ServiceBusQueueTrigger) via Function parameters, and following this you can execute another task such as writing to an Azure Table Storage NoSQL Database by using the return value of the Function.

Serverless Microsoft Azure Functions (FaaS)
Prerequisites/Assumptions
I’m going to assume that you are familiar with Azure Service Bus topics/subscriptions, the publish-subscribe pattern and Azure Table Storage.
Let’s Code
To begin, let’s grab a copy of the Azure Service Bus Publisher implementation that I open sourced on Github from a previous blog post. This is going to act as our publisher of messages to an existing Service Bus that we have setup in Microsoft Azure.
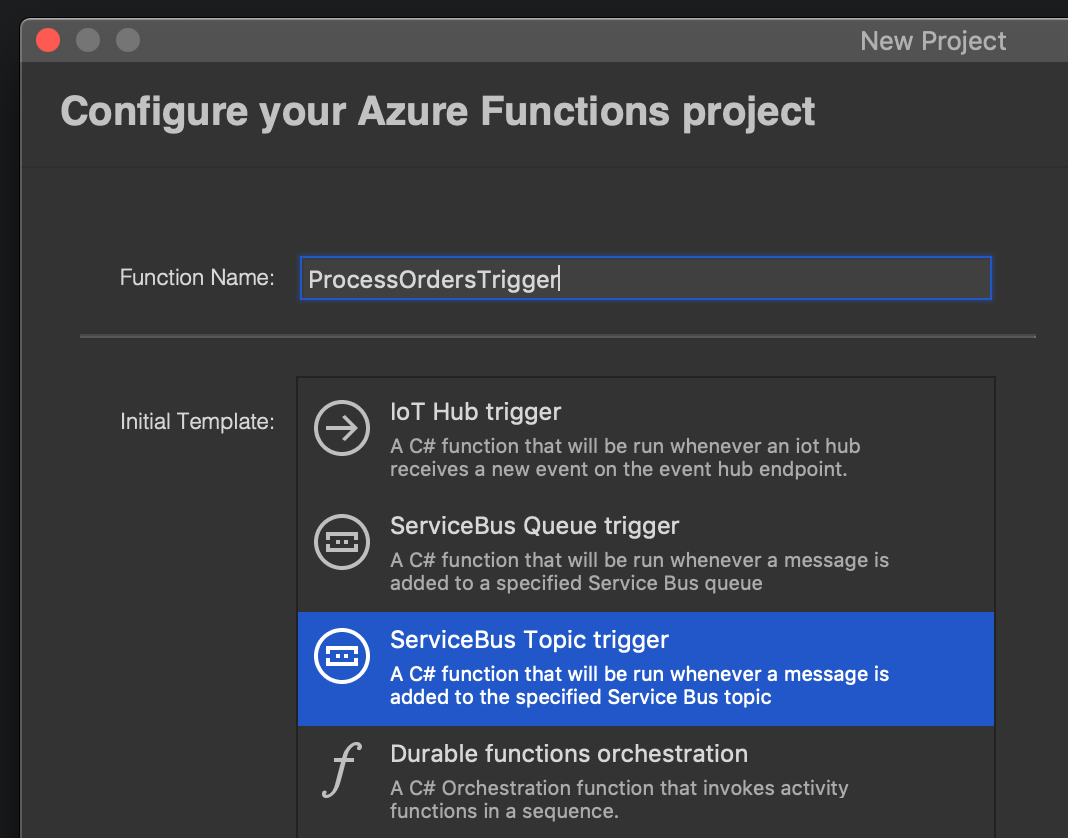
Head to Visual Studio and create a new Azure Functions project. We’re going to be processing restaurant orders from our Service Bus message queue as per the previous blog scenario we were working with, so lets keep the naming conventions inline with that for clarity. Ensure you choose “ServiceBus Topic Trigger” (and not the queue trigger which doesn’t support pub-sub).
Serverless Microsoft Azure Functions (FaaS)
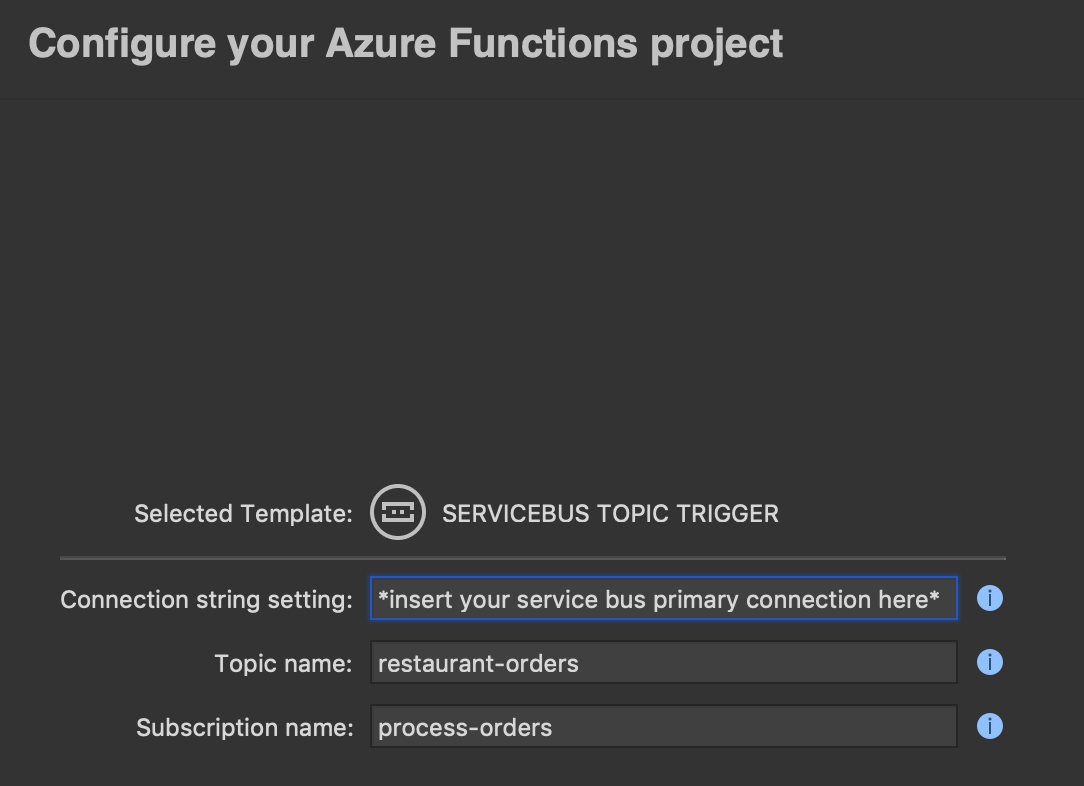
The next thing to do is supply our Azure Service Bus primary connection string value, topic name and subscription name to our Azure Functions project.
Serverless Microsoft Azure Functions (FaaS)
Finally, name your project solution file and click create, and you’ll see the following Azure Function has been created with the values that we entered when creating the project.
As you can see, our function has a relevant name and accepts 3 parameters initially - our Service Bus topic, subscription and primary connection string, followed by a message string and a logger. It also returns void, because when triggered it simply runs and isn’t bound to an external service…yet.
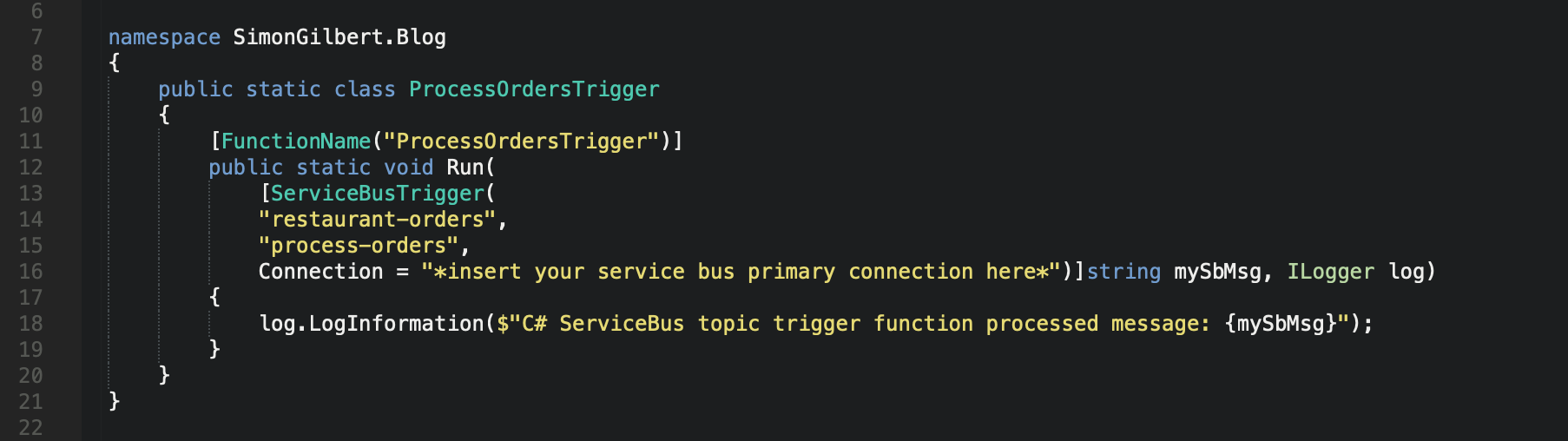
Serverless Microsoft Azure Functions (FaaS)
We’re going to make some changes to this functions file, but first let’s bring our Nuget package dependencies up-to-date and ensure we’ve pulled in the following packages to our main project -

Serverless Microsoft Azure Functions (FaaS)
Ok, we’re now ready to amend the Azure Function to allow it to receive pub-sub messages from our Service Bus and write them to a local Azure Table Storage table. Pull in a copy of the view model from our publisher project that I mentioned earlier, and ensure it inherits the TableEntity class from Azure’s Table Storage package.
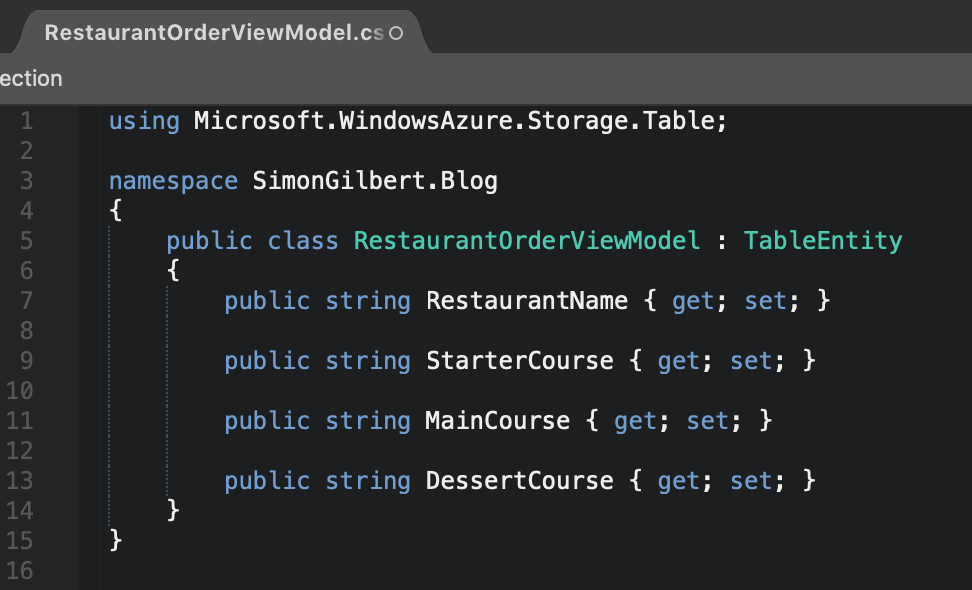
Serverless Microsoft Azure Functions (FaaS)
Next we can head to the local.settings.json file, and note that it looks as follows, with a blank value for the AzureWebJobsStorage key.
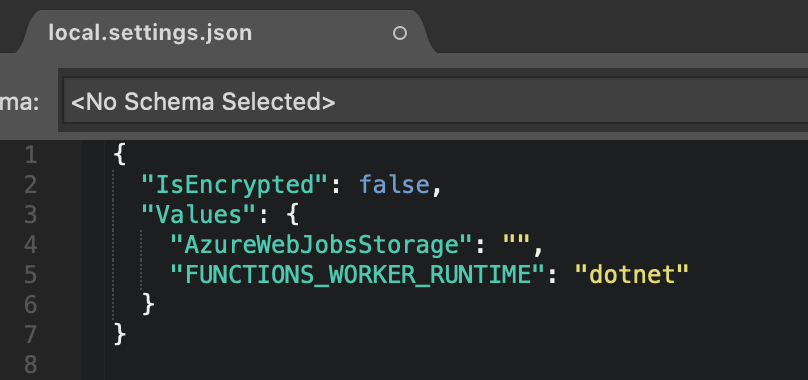
Serverless Microsoft Azure Functions (FaaS)
Let’s update these binding pairs with values for configuring our Azure Function and local Azure Table Storage setup.
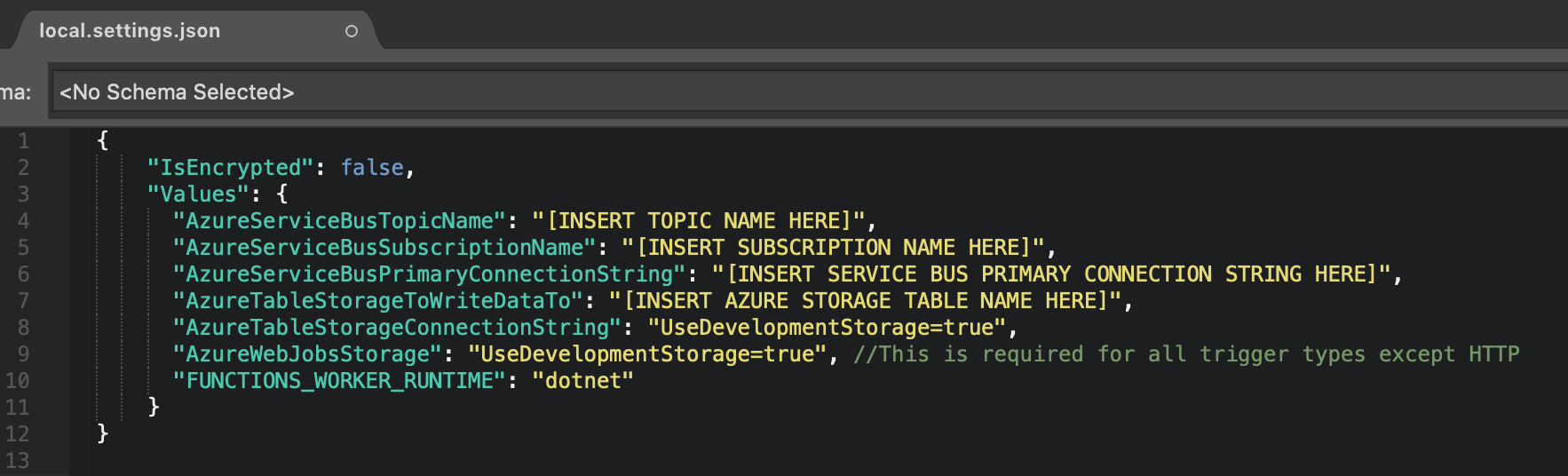
Serverless Microsoft Azure Functions (FaaS)
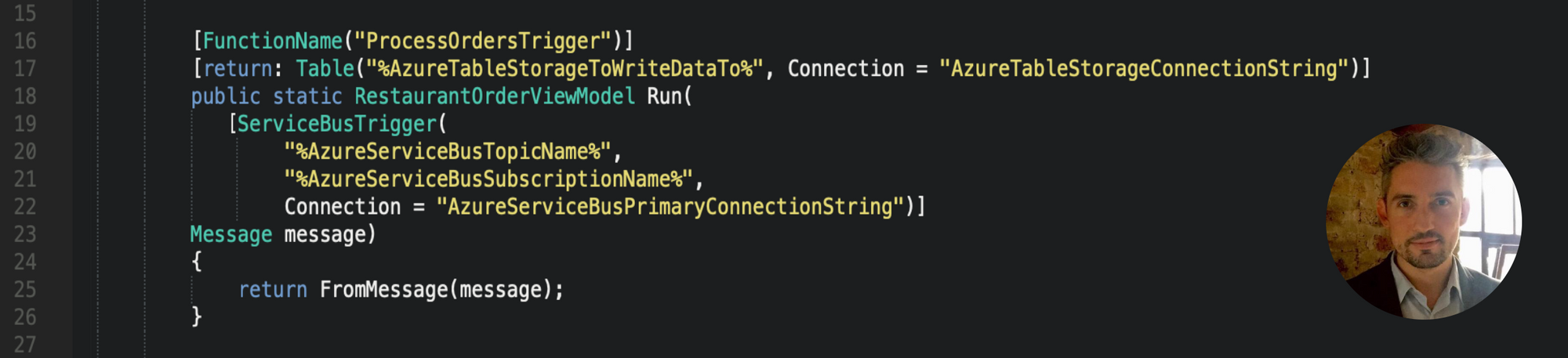
Now that our settings file is configured, we can pull in these values to our Azure Function source code. The first change that we’ve made is to pull in the Service Bus topic name, subscription name and primary connection string from our local.settings.json file. We’ve also added a parameter of type Message, which is the Message class used by Azure Service Bus to send messages across the queue from our publisher. We are telling our Azure Function Trigger to “accept” messages from our Azure Service Bus, that conform to the same class definition.
Next, we want to return an instance of our RestaurantOrderViewModel to Azure Table Storage, so we’ve amended the Run method from being void, to accommodate this, and added a “return” attribute above the Run method, and specified an Azure table name to write our data to along with a connection string - which are pulled in from our local.settings.json file.
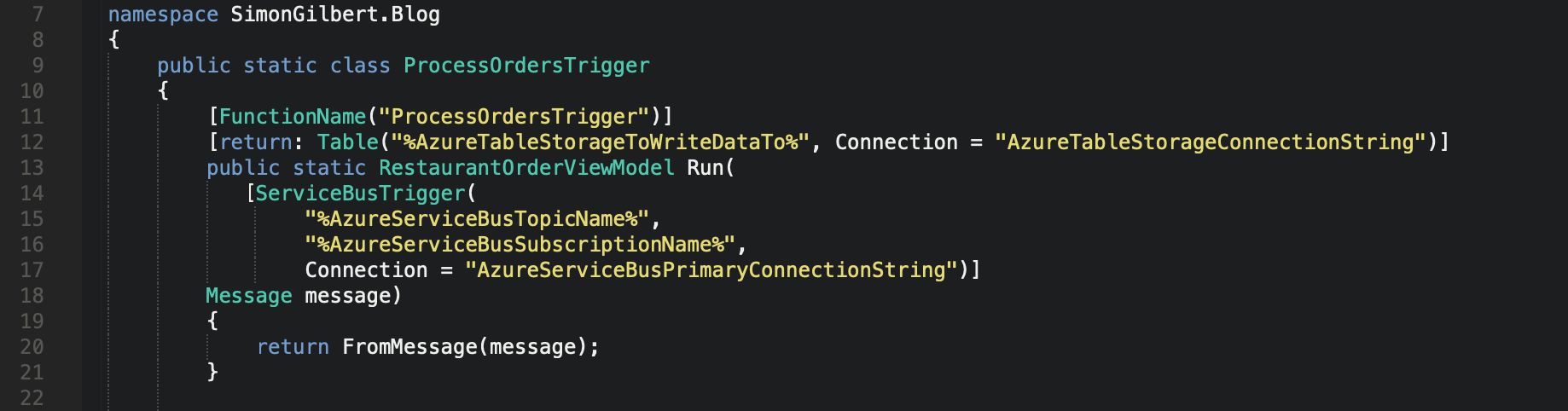
Serverless Microsoft Azure Functions (FaaS)
Now you can see the body of the method is calling another private method that we’ve implemented called “FromMessage”, so let’s add that into our Function class also.
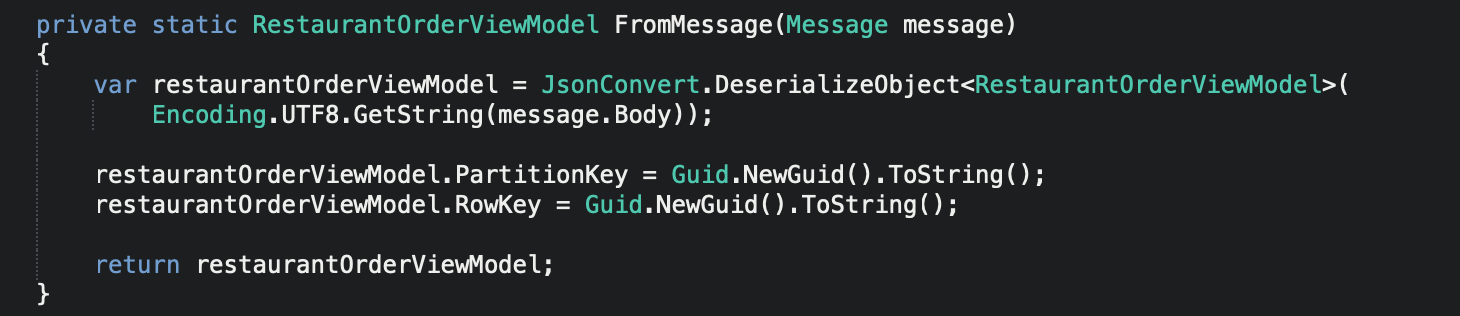
Serverless Microsoft Azure Functions (FaaS)
Here we are merely deserializing from our received Service Bus message back to our local data model, and then setting the necessary PartitionKey and RowKey fields that Azure Table Storage requires in order to create a new row in our local table.
Finally, let’s run our Azure Function alongside our Azure Service Bus Publisher and watch the magic happen!

Serverless Microsoft Azure Functions (FaaS)
…excellent, and if we head to our local Azure Storage Explorer emulator and view our “RestaurantOrders” table:

…result!
Enjoy!